by Josh Shepard on 2024 | 04

Bottom Line Up Front
Threat actors are crafty when it comes to social engineering. They will do anything in their power to trick a user into clicking the malicious link, downloading the bad file, or coughing up sensitive data. Today, we’ll be talking about a tricky method of URL obfuscation that leverages RFC1738 abuse, alternative IPv4 representation, and homoglyphs to make a bad URL look benign.
Background
As mentioned above, URL obfuscation is the process by which threat actors make malicious URLs look benign. The classic example of this is character substitution, where something like google.com is written as g00gle[.]com. However, this is just the tip of the iceberg. In this post, we’re going to cover several different URL obfuscation techniques that, when combined, can give us a link like the one below:
https://tools.usps.com∕go∕TrackConfirmAction.action_tLabel=2816532912364831@2130706433
Looks legit, right? However, if we copy and paste this link into our browser, we get a surprise:
If you want to test the link yourself, feel free - it will just navigate you to 127.0.0.1 as seen in the GIF. I promise this isn’t an open redirect bug on the USPS website but just several different URL obfuscation techniques stacked together. Let’s break down what’s going on here.
Step 1 | RFC1738 Abuse
RFC1738 is what defines the structures of URLs. When we talk about URLs, the first protocol that comes to mind is HTTP, but the concept of a URL applies to many different protocols including FTP, NNTP, Telnet, and Gopher. RF1738 defines the common URL scheme syntax and then adds more guidelines, syntax, and restrictions based on specific protocols. With that high-level introduction out of the way, let’s talk about RFC1738 abuse. This part of the blog will heavily reference some great research that Mandiant published last May - Don't @ Me: URL Obfuscation Through Schema Abuse. Mandiant walks through how the base structure of a URL is as follows:
<scheme>//<user>:<password>@<host>:<port>/<url-path>
However, as we mentioned the RFC will discuss additional guidelines for specific schemes (protocols), so when we look at HTTP we see that it follows this structure:
http://<host>:<port>/<path>?<searchpart>
Neat. Notice that the HTTP structure does not have a <user>:<password>@ component, in fact the RFC specifically forbids using <user>:<password>@ in HTTP. So what happens if a user adds a <username>:<password>@ component to a URL? The answer: It just gets ignored! In fact, if you put an @ sign anywhere before the /<path> parameter HTTP will just ignore what comes before it. For example, if you were to enter:
https://google.com@bing.com
You would be navigated to bing.com because HTTP ignores what comes before the @ sign. You may have noticed above that I bolded the fact this @ has to be before the /<path> parameter. If you do it after the /<path> parameter HTTP will interpret the @ as part of the path. For example:
https://google.com/cooldogs@bing.com
Will generate a 404 at google.com because cooldogs@bing.com is not a valid google.com path.
Now let’s circle back to our sneaky link:
https://tools.usps.com∕go∕TrackConfirmAction.action_tLabel=2816532912364831@2130706433
As we can see in red, we do have an @ symbol but you may be asking yourself a couple of questions:
- What the heck is that number doing after the @ symbol, and why is it taking me to 127.0.0.1?
- Why is this working even though the @ symbol is after the /<path> parameter?
Let’s first address the first question.
Step 2 | Alternative IPv4 Representation
Did you know that IPv4 addresses don’t have to be written in dotted quad format (ex: 127.0.0.1)? The whole dotted quad format is just an easy way for us humans to remember a 32-bit label and so it became standard practice. However, computers don’t have that limitation. A modern browser will understand an IPv4 address written in hexadecimal, octal, or even decimal. For example, you can write 127.0.0.1 in any of the following ways and your browser will navigate you to 127.0.0.1:
- Hexadecimal: 0x7f000001
- Octal: 017700000001
- Decimal: 2130706433
Now looking back at the link:
https://tools.usps.com∕go∕TrackConfirmAction.action_tLabel=2816532912364831@2130706433
We see that the decimal string (highlighted in blue) is actually a decimal representation of 127.0.0.1.
Now, the final question remains: How does this still work even though the @ symbol falls after the /<path> parameter?
Step 3 | Homoglyphs
To put it simply, homoglyphs are letters or characters that look similar. For example, the English letter ‘a’ and the Cyrillic letter ‘а’. To the human eye these letters are identical, however to a computer one of these letters is the Unicode encoding ‘U+0061’ and the other is the Unicode encoding ‘U+0430’. In other words, they are two very different letters. This fact has been long abused by threat actors making use of homoglyphs in domain names (we’ll have a separate blog post touching on this and the advent of punycode). For our purposes we need to figure out a homoglyph for the forward slash ‘/’ that indicates the /<path> parameter. This way, we can make the user think there is a /<path> parameter when, in fact, there is not. After a bit of Googling we find the division slash ‘∕’ which looks very similar to forward slash ‘/’ used in the /<path> parameter. However, the computer views the division slash as an entirely different character than the forward slash, meaning that a browser will not process it as a path.
https://tools.usps.com∕go∕TrackConfirmAction.action_tLabel=2816532912364831@2130706433
As we can see in purple above, the division slash blends in very well, masquerading as a forward slash
Step 4 | Putting it all together
Combining all the steps above we now know how the obfuscated link is put together and where it will direct an unsuspecting victim:
 How do I protect myself from this sort of attack?
How do I protect myself from this sort of attack?
User Education
Even with an obfuscated link like this, if a user hovers over it in an email body, most email clients will still show the destination of the link.
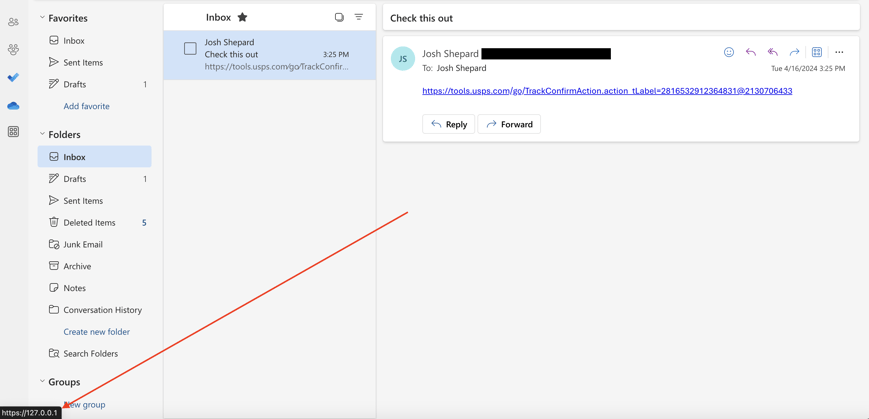
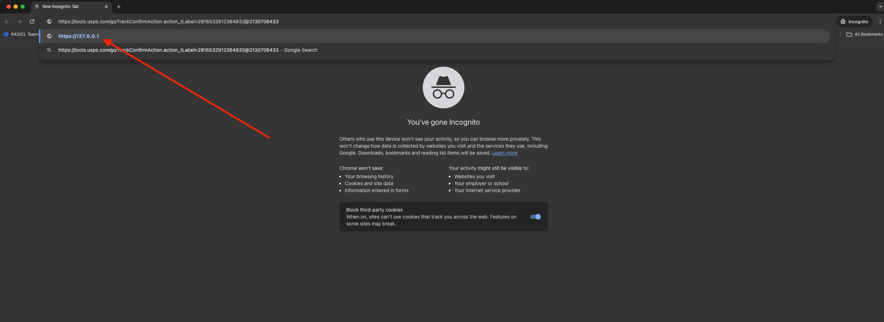
The same goes for when a user copies and pastes the URL into a browser, the browser will still show the destination of the link in the drop-down portion of the address bar.
Detection Logic
If you are collecting email security logs that contain the URLs found in the email message body, you can set up detection rules for homoglyphs in those links as well as unusual @ symbol placement

A Day in the Life: The RADICL vSOC Responds to the CrowdStrike Incident

RADICL Detection Spotlight: Multi‑Stage VBScript Malware Analysis

No Comments Yet
Let us know what you think